
What is a Data Fabric?
A data fabric, a design concept in data management, consists of multiple tools and processes to manage their data efficiently. It leverages existing tools, platforms and administration tools to assist organizations manage their data efficiently. A data fabric provides access across multiple data silos, whether on-premise or in the cloud, adding technical metadata and automating the orchestration of multiple tasks.
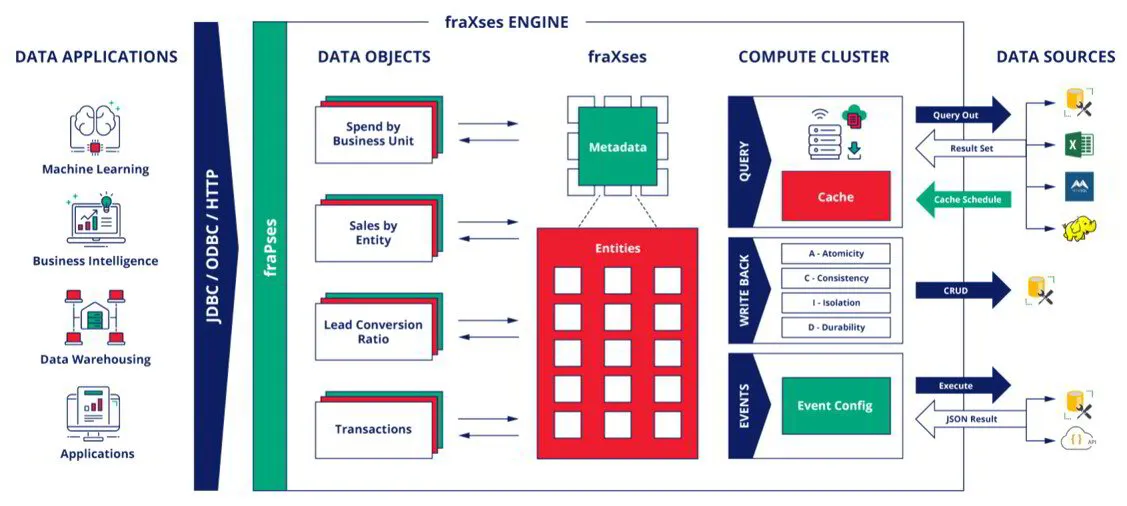
The goal of a data fabric is to maximize the value of your data by providing real-time insights to:
- Streamline and improve decision-making
- Uncover new business opportunities
- Create visibility of the entire end-to-end supply chain
- Improve the whole customer experience
- Generate new revenue streams based on the inherent value of data
- Create client insights through open source intelligence
A data fabric provides immediate business impact without interfering with daily operations, while providing complete visibility into where data originates from, how it is transformed, and where it is moved to during the advanced analytics process.

Connect, Don't Collect
Data is stored in many different forms - structured and unstructured - in different types of data bases, spreadsheets, PDF files, social media and news feeds, email, voice-recordings, business feeds, application feeds, data warehouses, and many more - on premise, or in the cloud, or behind portals.
Some of this data is static while others, deliver data at very high velocities and need to be processed and stored in real-time.
The original raw data sources represent the single source of truth. Others represent transformed and aggregated data, no longer discernable as the original source of truth, and with no record of the aggregation / transformation process it underwent.
Storing data is very expensive with storage requirements growing at 50-100% year-on-year. Less than 0.5% of an organization’s data is utilized in any analytics process.
The proven data federation approach employed by Fraxses connects any and all data sources to the end-to-end Fraxses data fabric for advanced analytics purposes.
In this sense, it creates a single virtualized data lake of all organizational data for analytics, machine learning and AI.

From Fractured to Federated
Traditional approaches to data management weren’t built to handle today’s data volumes and streaming velocities. As a result, data ends up in siloed databases as “dark data”, with limited user access.
Organizations have tried to solve this by moving all this data in large data lakes, which they claim represents their new single source of truth. However, these data lakes lack intelligence. It is extremely complex and often expensive to retrieve the right data for a given purpose or use case.
Fraxses can federate all these disparate data silos and external data sources without moving the data, thus creating a virtualized intelligent data lake with all the discovered relationships between the various data elements appropriately validated.
Accelerated Data Engineering
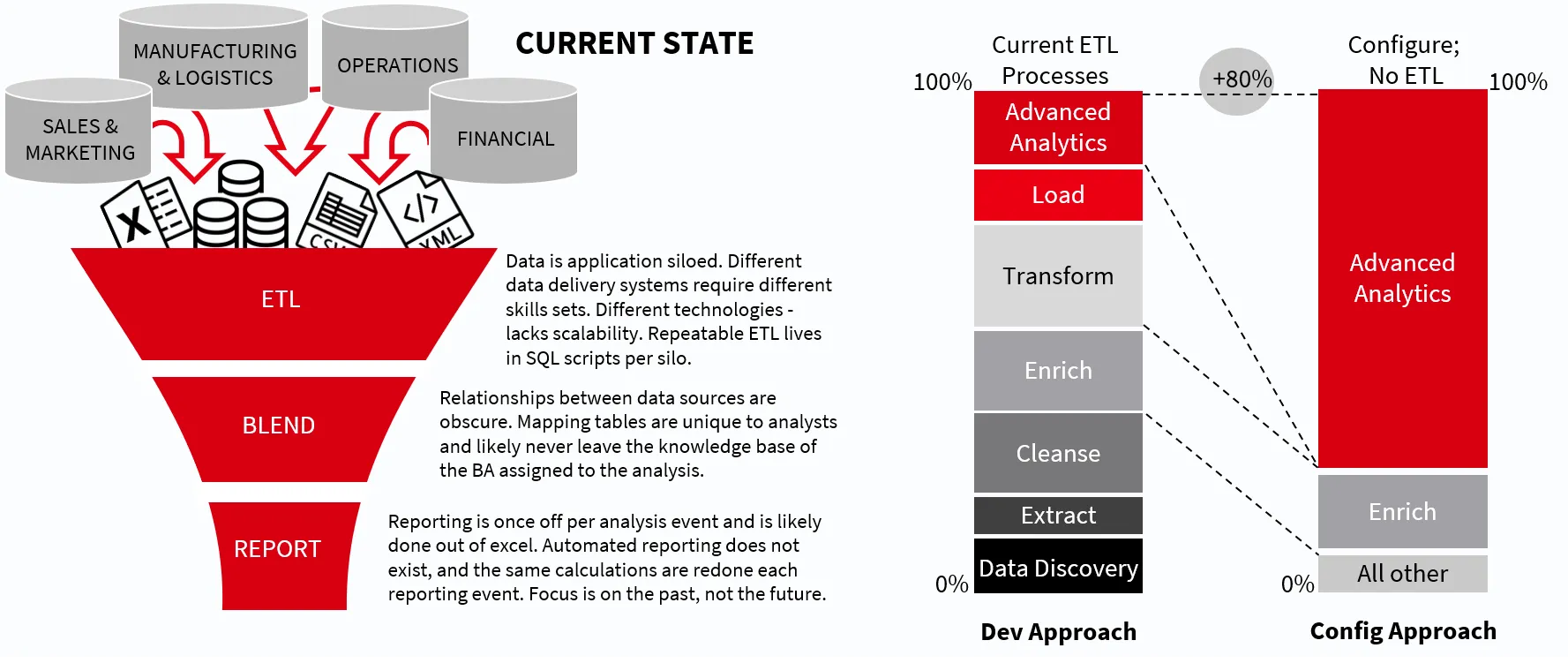
The data engineering process encompasses the overall effort required to automate the transfer of data from multiple data sources, transforming it into a specific format and making it available for a specific purpose.
In that sense, data engineering is an ongoing complex and time-consuming practice that involves collecting, preparing, transforming, and delivering data. It typically utilizes multiple ETL tools and approaches, often in a non-standardized manner, resulting in cost duplication and lengthy delivery times.
Fraxses accelerates the data engineering process by up to 80-90% through a configuration rather than a development approach, automated multi-key data discovery, the creation of re-useable data “views”, and the extension of the data fabric’s capabilities using its micro services architecture.
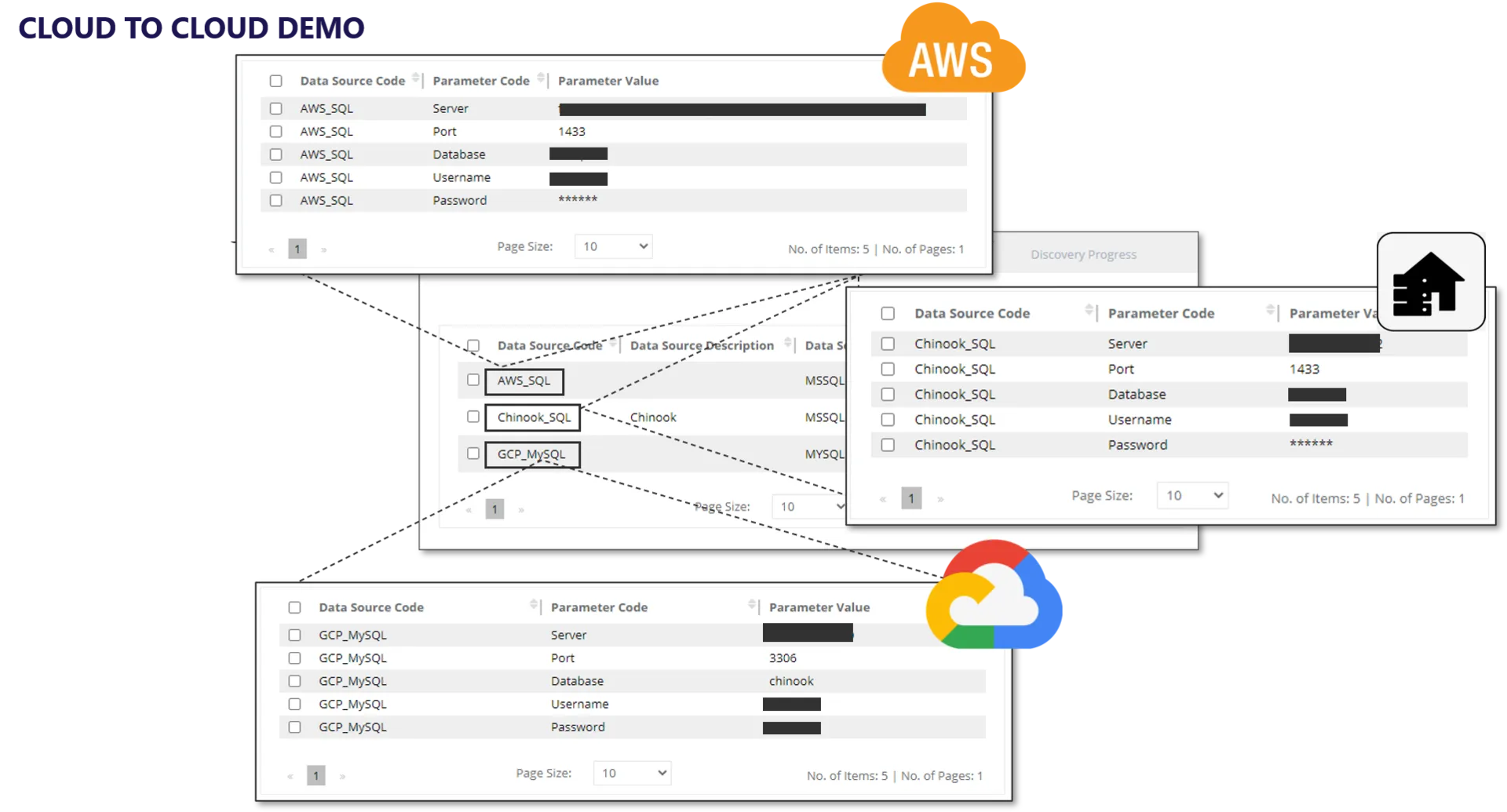
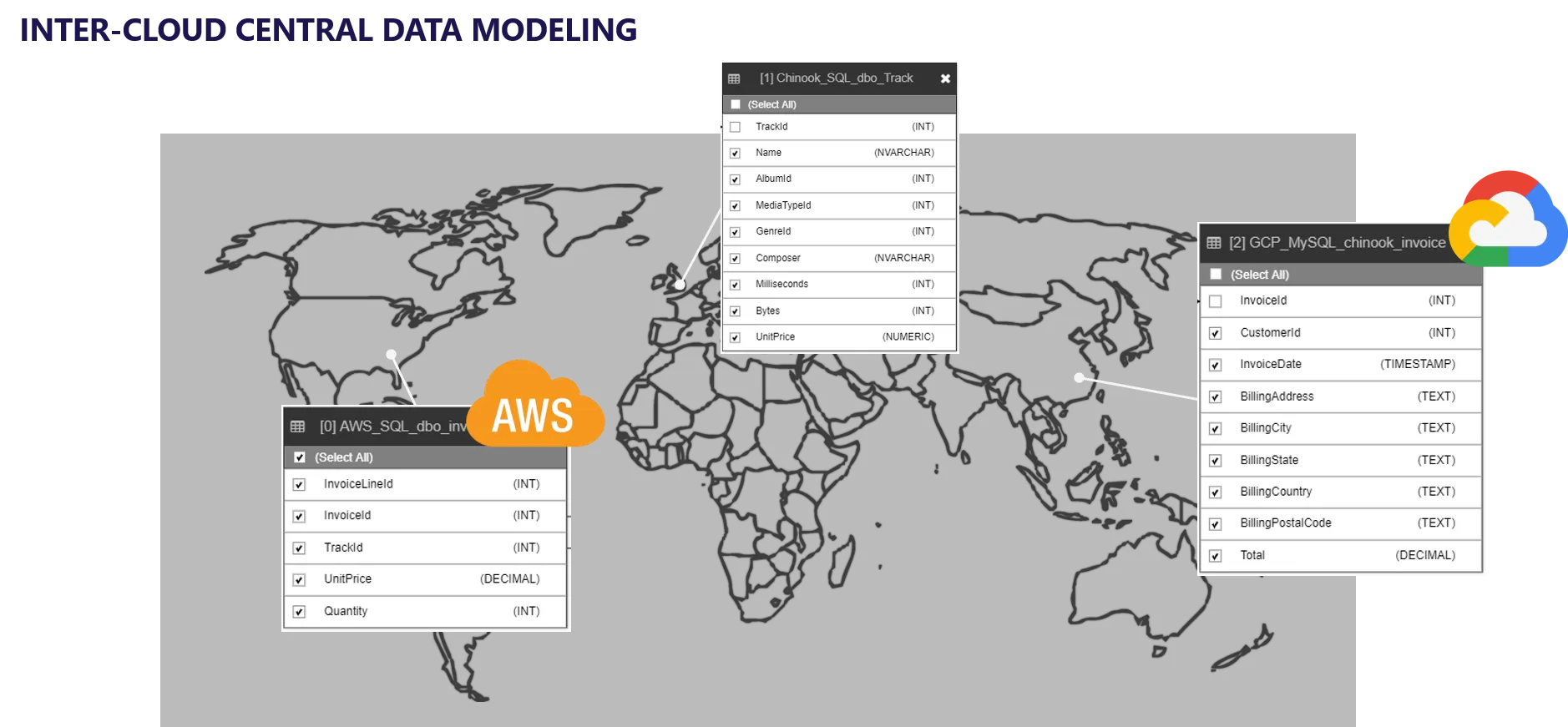
Multi-Cloud Data Orchestration
Organizations are increasingly moving applications and data to the cloud, or as in many cases to multiple clouds [e.g. Google, Amazon or Microsoft Azure]. However, most organizations currently employ a hybrid environment with legacy data on premise and new applications in the cloud.
This creates a number of challenges.
- What is the best way to migrate data to the cloud?
- How do I repatriate data to my on-premise infrastructure?
- Can I model my data across clouds, and if so...
- How do I orchestrate my data across a hybrid, multi-cloud environment.
Fraxses, with its write-forward / write-back capability simplifies data migration and data repatriation. Likewise, the Fraxses data federation and data virtualization capabilities is the perfect cross-cloud data orchestration platform.
Data-as-a-Service
An inherent goal of most organizations is to make data available across the entire organization, user access authorization permitting, to increase productivity, aid better decision-making and control streamlined access to the single source of truth. This is often referred to as data-as-a-service or a unified data delivery platform.
Fraxses’ data federation capabilities can provide connectivity to all global data sources.
Fraxses’ data virtualization capabilities enable the creation of reusable data views that can be standardized and made available as an organization-wide standardized library and service catalog.
Various data views can be combined to deliver a particular service which can be cataloged and provided as standardized services.
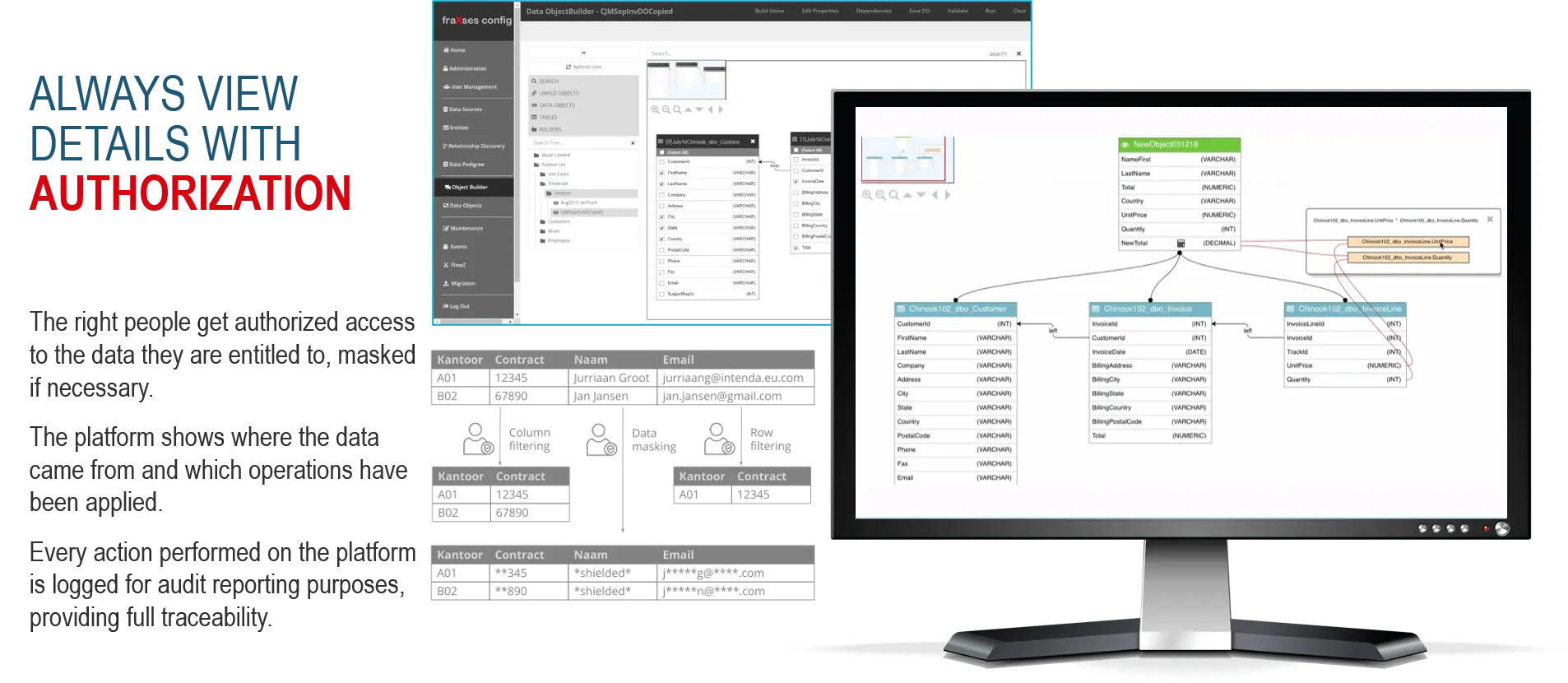
The security and audit logging capabilities, enables people to have controlled or reduced access to the data they need to perform their various functions and tasks, across the organization.

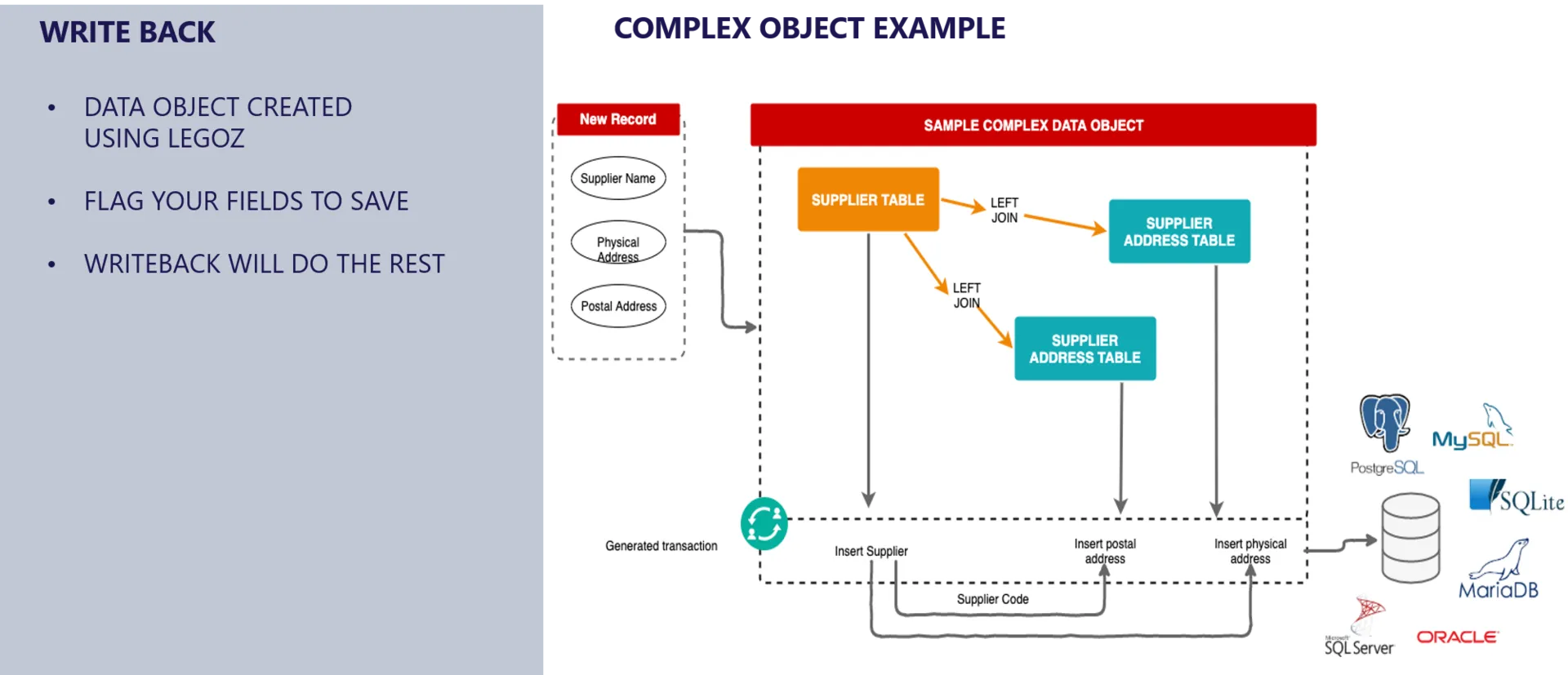
Write-back
Traditionally, BI, data warehouses, data lakes and data virtualization servers are deployed in read-only environments, and while this may be sufficient for most data consumers, certain data consumers need to be able to change data as well, such as update or delete their addresses or contact details, or place new orders, or enter budget and forecast numbers.
With its new release, Fraxses can update, delete and insert data into the underlying data sources.
Fully Secure and Auditable
Advanced data security allows column level security, row level security and masking on data made available through Fraxses. Access to the data is restricted by assigned user access policies.
Every microservice in the ecosystem logs all activities: error and information messages with accompanying memory profile, environment details and versioning information.
Every request is assigned a unique request ID which can then be used to track all events and log messages associated with that ID.
Use Cases
Ledger Consolidation
Full Transactional Audit
Merger & Acquisitions
Global Logistics Management
Complete Operating Picture
Unified Data Services Layer
Human Capital
Revenue Assurance
Blockchain
Governance, Risk & Compliance
IT Modernization
Client Insights
Anomaly Detection
Anti-money Laundering / Fraud Detection
Identity Resolution
Open Source Intelligence
Customer 360
Data Monetization
Business FAQ's
You claim to sell smart solutions that enable better, faster decision-making. What does that mean?
Better decisions are made if one has timely access to complete, up-to-date, trustworthy information, in real-time. Fraxses works across all relevant data sources, internal and external to the business, relative to the decision in question, performing the necessary actions/processes in real-time to create accurate, timely insights or trigger events, as the case may be.
There is no pre-processing of data to create an aggregated view, such as in traditional BI or Data warehouse systems. If your business changes, such as an acquisition or merger, new data sources can be added in hours and days to ensure complete visibility of all new data points. Thus, Fraxses enables better, faster decision-making.
Why does this sound too Good to be True?
It only seems like that, because we are all so familiar with the convoluted, traditional approaches to working with data such as BI, Data Warehouses and Data Lakes, all of which require significant and diverse technical skills and long lead times before expected outcomes are delivered. One only has to refer to customer testimonials to realize this new way works!
Will Fraxses work for my Business?
Fraxses solves big data challenges, whether they be in finance, manufacturing, customer / vendor management or HR or across the whole enterprise. If your business needs to make sense of diverse data sets with large volumes and/or high-speed data sources, in real-time, then Fraxses will work for your business. Challenge us. We know very quickly if we can solve a particular problem. If we can't prove it within 2-3 weeks then we will tell you and walk away.
You say Fraxses is "enterprise-ready”. My people aren’t technical. Can they make use of Fraxses without deep technical knowledge.
The ability to create standardized data views and data products means that non-technical users have access to a library of re-useable modules that are proven to work and can be “configured” quickly to generate a new query pertinent to that user. Our most successful clients create an internal Fraxses centre of excellence to drive enterprise-wide adoption.
We have made significant investments over time in a variety of data projects including our new data lake project. Are you suggesting we ”rip and replace” what we have in place already?
Absolutely not. Fraxses co-exists in a symbiotic relationship with your existing technologies. They become the data sources for fraXses.
Over time 3 transitions emerge:
[1] Fraxses becomes a unified, standardized access layer for all data warehouses, data lakes, operational data stores and BI systems;
[2] organizations reduce their need for an enterprise data visualization product [e.g. Tableau] as the visualization capabilities in Fraxses meet 80% of the user’s requirements.
[3] data duplication is reduced or eliminated through the data federation capabilities in Fraxses. There is no need to move data for the sake of moving data. Data is only moved if the Use Case requires it.
Technical FAQ's
How does your product use AI (Artificial Intelligence)? Explain the AI based features.
The main two ways that Fraxses uses AI is through the data relationship discovery engine and the cost optimization of queries. Data relationship discovery is one of the most advanced tools in Fraxses and is used to automatically discover relationships between tables, a precursor to understanding any data landscape. When a database is connected to Fraxses, Fraxses automatically identifies existing relationships and maps them for later verification and use within Fraxses.
The second, more powerful use, is when fraXses connects to multiple databases across 2 or more silos. fraXses can discover and suggest relationships between tables and columns across multiple databases. For instance, if an Oracle database and an AWS data lake were connected to by fraXses, fraXses would be able to discern the relationships within each of those separate databases, and then suggest new relationships based on the mapped databases, often discovering relationships previously unknown to the business, especially when working across application silos.
Cost optimization is the second way fraXses uses AI. When a data object is created, the fraXses engine manages the join pushdown to data sources, the aggregation pushdown and the filter pushdown. This means that when a data object is in use, fraXses has already prepared the fastest way to access that data from the different data sources and aggregate them in the most efficient way possible, inclusive of the time needed to filter and aggregate the data. What the end user experiences is a seamless aggregation of data sources that appears to them as a single logical database, without having to worry about where each bit of data is actually stored, and with a very fast query return time.
It is also worth keeping mind that fraXses allows any AI/ML technology to be "plugged in" which will then accelerate AI/ML projects given that the data virtualization layer creates a virtualized data lake across all distributed data sources for AI/ML use cases.
Lastly, should a text analytics capability be needed, then fraXses provides a NLP technology OEMed from Basis Technologies called Rosette, which is fully integrated into the fraXses stack. Rosette uses AI extensively across it's many text, open-source intelligence and identity-verification functionalities.
Does the tool support configuration? What are the limitations?
Yes, Fraxses is a no-code, configuration platform. The set of Fraxses configurator tools uses physical and logical data objects to describe the logical data architecture, using only the data components needed by the use case. This allows data from all sorts of different databases to be represented in a group of virtual tables. Accessing data in more traditional ETL and other data integration tools requires a knowledge of a variety of languages SQL, JSON, etc. Fraxses uses SQL99 as its primary "config" level language and fraXses does the necessary parsing of instructions to the correct language where necessary. Effective data governance and control is enabled through real-time data pedigree, data lineage and audit logs.
Does the tool support customization? What are the limitations?
Yes. Fraxses is extremely customizable.
[1] Fraxses offers a unique microservices architecture, which is fully extensible. By leveraging the containerized nature of this architecture, Fraxses can be made to use any size and any format of microservices, from those that are packaged with Fraxses to microservices customized by developers for specific purposes. These function through calls made to the Fraxses gateway service, which then passes them off to a coordinator to request and activate the necessary microservices . Each microservice is designed to do one task efficiently and without breaking, and is also elastic, resilient, minimal, and complete. In essence, each microservice is good at exactly the one task they’re assigned, and they can be swapped out or added in at a whim. By combining all these microservices, Fraxses can accomplish a robust and complete set of tasks quickly and efficiently, scaling vertically or horizontally, as required.
[2] Developers can bypass the config capability importing scripts in their preferred languages [SQL, Python, etc.] using Smart Language Wrappers. The smart wrapper provides the ability to run serverless code in isolation with unified communications, encryption and logging in the component language.
[3] Coming in Q3, 2021, there will be a low-code application configuration add-on to Fraxses, in terms of which full applications can be built on top of Fraxses.
What are your Security and Privacy Standards and Policies, including your encryption practices?
Fraxses ships with a robust data security and privacy implementation. Data access is role- and group-based, which includes permissions for accessing specific datasets, columns, rows, and can provide data masking for sensitive data. In terms of security and privacy standards (GDPR, NIST, or ISO 27000), we can configure security compliance to meet them. In fact, Fraxses can be configured to manage GDPR compliance, for example.
Calls to the API and configuration modules are made over SSL. Encryption for all the microservices in the cluster is done through three-way encryption using TripleDES, however any algorithm can be plugged in with minimal development. For encryption of data-at-rest for the different cloud providers, we use the storage they supply with encryption; for On Prem this is facilitated via Ceph.
Does your solution have pre-built or easily configurable integration with any common log aggregation and monitoring solutions? Who are the vendors and what is the solution architecture?
Yes.
Fraxses uses the ELK Stack to monitor and collect log data. ELK (Elasticsearch, Logstash, and Kibana), along with Filebeat, creates a robust logging and monitoring system. Filebeat is used to listen for changes to log files and then pass those changes to Logstash. Logstash acts as a real-time data pipeline and pre-processor, which then feeds into Elasticsearch. Elasticsearch acts as the backbone of the log store and search. It is scalable and runs on large volumes of log data in near-real-time. Kibana sits on top of these pipelines in an easy to access web interface and allows for a variety of analysis and visualization. For instance, Kibana can be used to check specific log files for anomalies, or it can display and manage the health of the Fraxses cluster. With all of these combined tools, Fraxses offers a versatile and powerful logging platform that covers every aspect of the data and software.
What analytical languages (Python, R, SQL, etc.) does this platform support?
Fraxses has a backend that is compatible with SQL99 as the main language. It uses a configuration approach as the primary way to manipulate data, however. Fraxses uses wrapper libraries for languages like Python to allow developers to use python alongside Fraxses, where Fraxses would interface with the wrapper and then the wrapper would handle communication between the code and Fraxses. What this means practically, is that developers using their own code would never need to interact directly with Fraxses internal systems. If the backend is changed from streaming data from Kafka to using a different service, the user wouldn’t have to change any line of code, it would just continue working as it always had. This essentially means that end users won’t have to worry about what database or stream changes take place, and database engineers don’t have to worry about breaking code when they switch to newer, better data storage solutions.
The easiest way to manipulate data within Fraxses is through REST APIs or through the Flowz event engine. Fraxses comes preinstalled with a large number of useful events that can be used to prune data or manipulate data from various data sources and sinks. The general idea is that Fraxses grabs X data from tables or columns, then pushes it through a set of events, either ones preinstalled with Fraxses or custom written ones, to create Y dataset from the original X data. This new data is pushed to a sink database, which could be the same database or a new one.
In terms of how an end user would interact with the data they receive from Fraxses, they shouldn’t have any restrictions on how they can manipulate the data for analytics purposes. For instance, a user that wants to use Python to visualize data would be able to set up a connection with Fraxses and query the data.